Engineering Multi-Agent AI Systems

We are seeing more and more multi-agent AI systems in biomedical research, from Google's Co-scientist to Robin's automating scientific discovery agents. In these systems, multiple agents—each an LLM that uses tools to perform actions and analyze results—work together to solve complex problems. Architectures for these systems vary substantially, which raises a key question: are there good, generalizable design principles for building them?
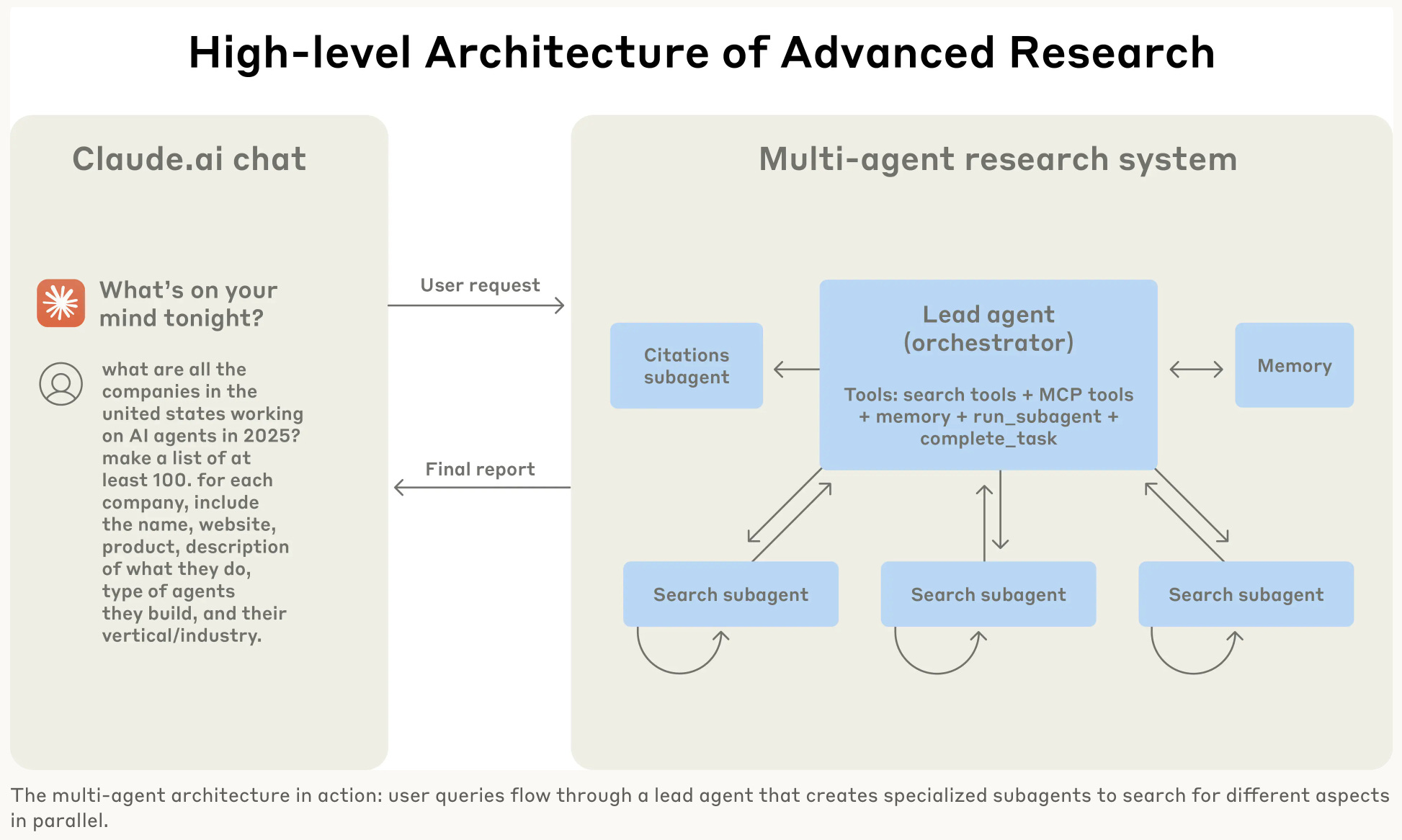
A new report from Anthropic on how they built their multi-agent research system offers a valuable look under the hood and some compelling answers. I think the core finding is quite interesting: their multi-agent system outperformed a powerful single agent by over 90% on research tasks, a boost driven largely by efficiently scaling the number of tokens used to solve the problem. Of note, these gains come at a cost, as multi-agent systems can use about 15 times more tokens than standard chat interactions.
I think the report's design lessons are broadly applicable and confirm what many of us have observed:
🔹 The orchestrator-worker pattern, where a lead agent delegates to parallel sub-agents, is a powerful architecture.
🔹 Detailed prompt engineering is the main lever for success, especially for teaching the lead agent how to delegate complex tasks clearly.
🔹 Massive performance gains come from parallelization, with their system cutting research time by up to 90% for complex queries by running sub-agents and tool calls in parallel.
Finally, I think the report offers a crucial dose of realism by detailing why the gap between a cool agent prototype and a reliable, production-ready system is so wide. Some of the key challenges include:
💥 Compounding Errors: Minor bugs can cascade into major, unpredictable failures because agents are stateful and run for long periods.
🐛 Difficult Debugging: The non-deterministic nature of agents makes bugs incredibly hard to reproduce and fix compared to traditional software.
🚫 No Easy Restarts: When an agent fails mid-task, you can't simply restart it from the beginning; this is expensive for users and loses all prior work.
These lessons on architecture, prompting, and evaluation are fundamental for the entire field.